AI (Artificial Intelligence) とはなにか
教科書によると、
「定型的な労働を自動化し、
言葉や画像を理解し、
基礎科学研究を支援する知的なソフトウェア」
とあります。
人工知能研究の初期の段階では、
「人間にとっては難解だが、コンピュータにとっては容易な課題を解決する目的」
で研究が進んでいきました。
人間がやると大変な作業を定型化し、コンピュータに任せる事で世の中の作業性は格段に改善しました。
これは現在のパソコンの普及を見れば、大いに理解できます。しかしながら、今ではこれはあまり人工知能とは呼ばないようです。
人工知能研究における研究のチャレンジ(難解な課題)は、むしろ
「人間にとって実行するのは簡単だが、形式的に記述するのが難しいタスクを解決する事」
の方でした。
画像認識や音声認識などは人間が行うのは容易だけれでも、コンピュータにおいてはアナログな情報の解析や、それをもとにした判断は大変困難で、これまでの手法では実現不可能であったわけです。
近年の人工知能業界の大きな盛り上がりは、これら画像認識や音声認識において、大きなブレイクスルーがあったためと思われます。
AIの研究はずっと昔から行われていて、現在に至るまでいくつかのブームも経験しています。
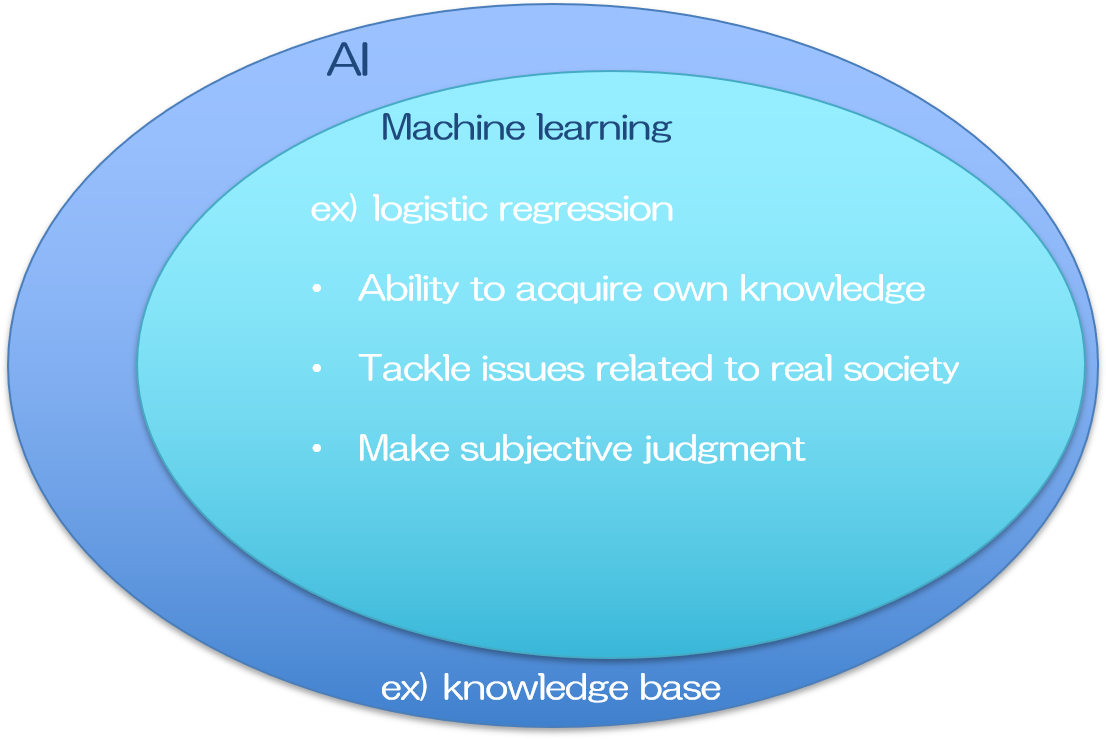
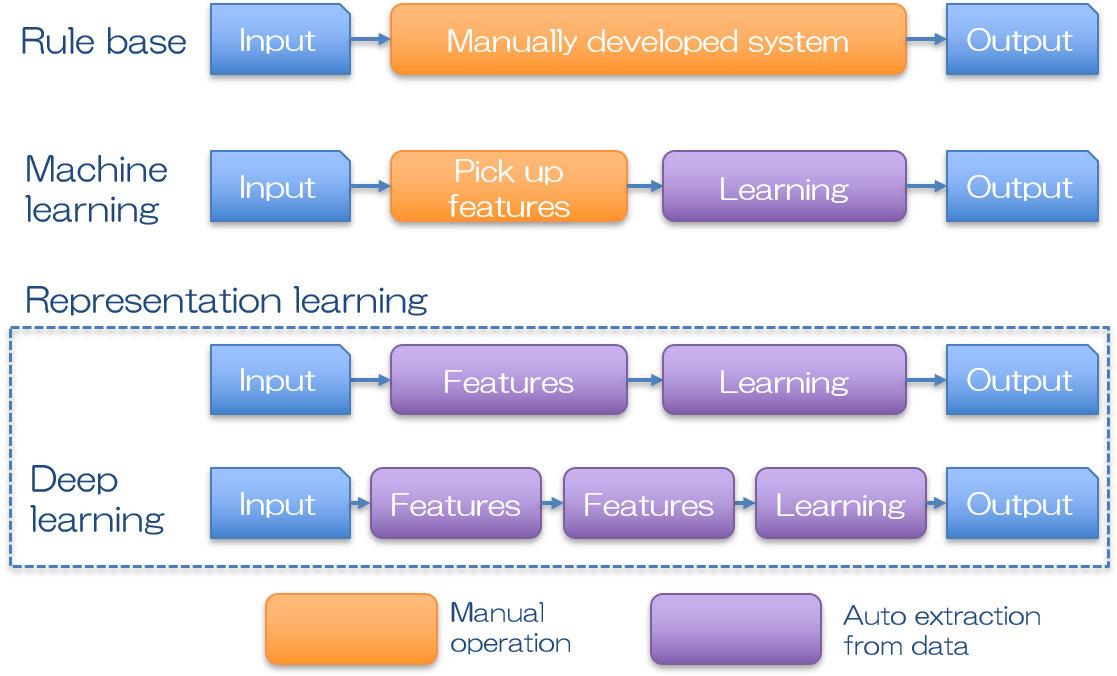
どこからを人工”知能”と呼ぶかは難しいところですが、初期の頃の人工知能は論理的なルール作成は全て人の手で構築されていました。
推論モデルを構築し、新しい結果を予測するために、過去のデータを用いていた事から、Knowledge Baseアプローチと呼ばれています。ここでは大量のデータの中からどの部分に着目するのか、そのデータをどのように扱ってモデル化するのか、など、全て人の手で行われます。従って比較的単純な課題であれば機能するものの、少し複雑なタスクになればその普遍的なルール作りが人の手に負えなくなり、期待した成果が挙げられませんでした。
そこでデータにおける普遍的なルールを自ら構築するシステムが考えられました。入力データに対して機械がルールの修正を自動で行う事で、徐々に正しい答えを導けるようになるプロセスが人間の学習と似ていた事から、これを機械学習(Machine Learning)と呼んでいます。
過去のデータを用いるので、結局はKnowledge Baseですが、複雑なルールで成り立つ課題であっても、大量のデータさえあれば何かしらの論理モデルを構築する事ができ、現実社会における問題を解決し得る答えを提供できる可能性があるため、大変な進歩を遂げたと言えます。
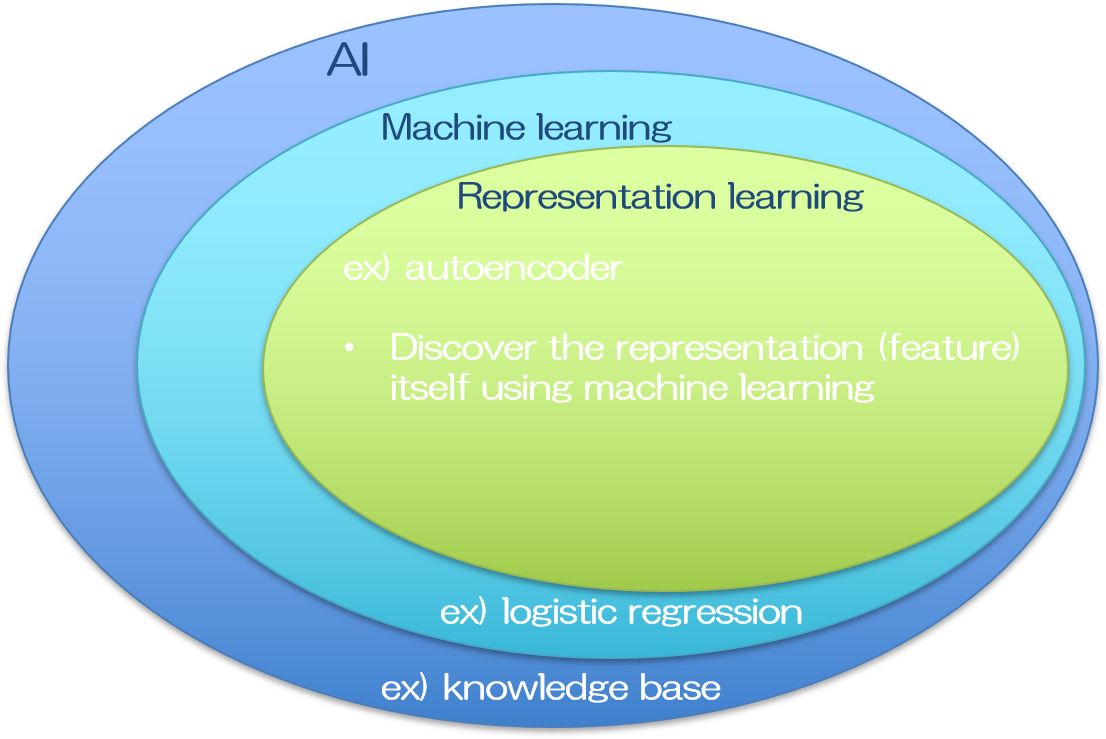
一方で、大量のデータの中からどの情報(特徴量)に着目するかは、依然人の手で指定する必要がありました。写真に写っているのが男性か女性かを識別するモデルであれば、男性の特徴は○○で○○である、女性の特徴は××で××である、など。
注目すべき特徴が明らかである場合は大変有効なモデルが構築できます。また注目すべき特徴をとにかくたくさん認識させておいて、どの特徴量が結果ともっとも強い相関があるかを調べる方法もあります。
しかしながら特徴量がそもそも曖昧なケースには適応できませんし、求めたい課題一つ一つに、有効な特徴量を検討する必要が生じ、わざわざ時間をかけてモデルを構築する用途は限られていました。
そこで注目すべき特徴量そのものも、入力データから自動で抽出できるシステムが考えられました。代表的なものに、ニューラルネットワークという機械学習の一分野を応用した、自己符号化器(オートエンコーダ, autoencoder)が挙げられます。
オートエンコーダは入力と出力に同じデータを入れて学習を行います。入力データはエンコーダで変換され、その変換されたデータはデコーダによって復元されます。デコーダからの出力は入力データと等価でなくてはならないので、デコーダの入力である、エンコーダで変換されたデータは、入力の中でも特に重要な特徴量を含むことになります。
このように特徴量まで自動抽出してくれるシステムを得た事により、人工知能は飛躍的に使い勝手が良くなりました。人間は入力データさえ持っていれば、あとは機械が全てやってくれます(理想的には。実際にはそうは行きませんが)。
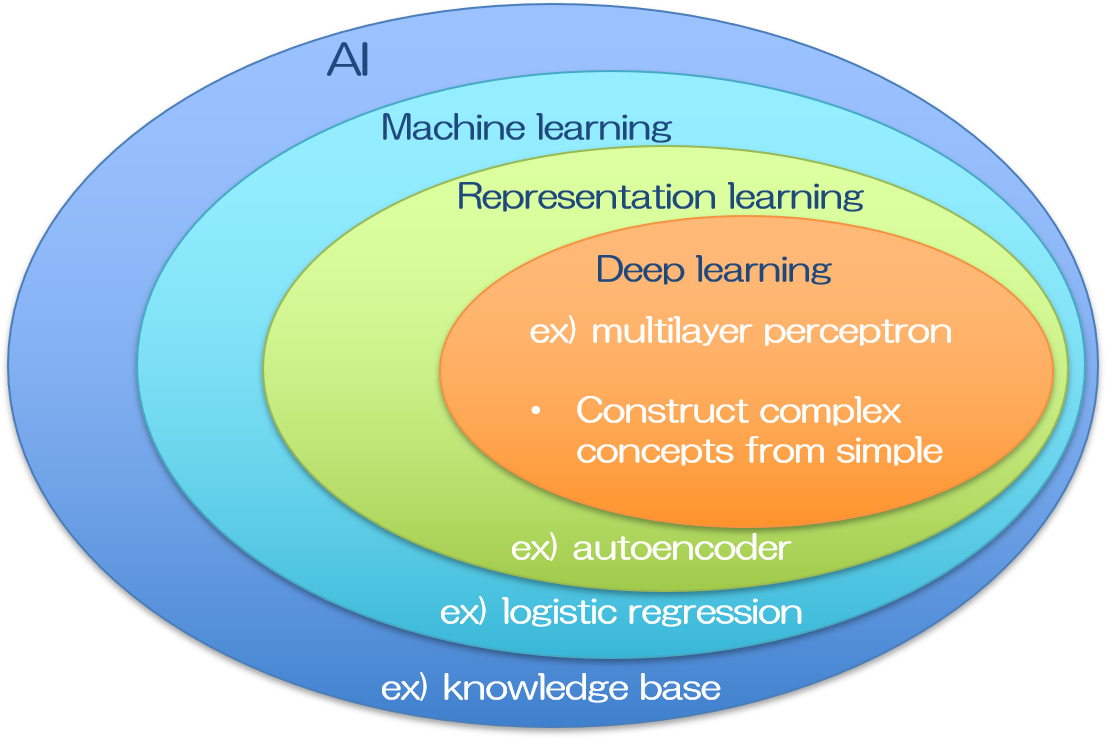
ちなみに機械学習と一口に言っても、その手法は多岐に渡ります。どの手法が究極的な人工知能を構築するのに適しているのか。長い間たくさんの研究が行われました。ニューラルネットワークはそのうちの一手法であって、ディープラーニングも昔からその構想は提案されてきた、概念自体は歴史の長い手法になります。精度の高いディープラーニングの登場によって人工知能の可能性は脚光を浴びる事になりましたが、将来的に究極の人工知能がどの手法を用いて実現されるかは、まだ分かりません。近年のブームをけん引するディープラーニングが注目されたのは、AlexNetの登場によるものと思われます。
人間の脳のニューロンを模したと言われるニューラルネットワークは、パーセプトロンの繋がりで表現される比較的シンプルな形をしており、層構造になっています。層を深くすればするほど複雑なネットワークとなり、同時に複雑な事象を表現できると思われますが、実際には層を深くするほど伝達される情報が少なくなる問題がありました。これは勾配損失と呼ばれています。上記のAlexNetはこの問題をReLU関数を活性化関数に用いる事で解決しました(と私は習いましたが、AlexNetの凄さはそれだけではないかもしれません)。
AlexNetの登場を皮切りに、勾配損失の問題をうまく工夫して回避する事で、ディープラーニングの層構造を深くすることができ、その結果として従来よりもネットワークの精度を飛躍的に向上させる事に成功しました。今では入力画像として猫の画像を大量に用意するだけで、写真に写っている動物が猫なのか犬なのか狸なのかを識別してくれるモデルが、誰にでも作ることができます。
人工知能の手法の分類には色々と異論があるところもあります。そもそも、それぞれの境は少々あいまいで、どこからの多層パーセプトロンがニューラルネットワークなのか、何層からのニューラルネットワークがディープラーニングなのかは、明確な定義はないそうです。またニューラルネットワークは機械学習の一分野なので、上記のベン図のように書いてしまうと、機械学習の最先端はディープラーニングしか無いように見えてしまいますが、他の手法も研究されています。
今後AI研究がどのような方向に進むのかは分かりませんが、現在は最先端のツールが安価で使えるすごい時代でありますので、その時代の恩恵に預り、ありがたく使わせていただこうと思う次第です。
[参考]
Ian Goodfellow著
深層学習 (Deep learning)
ASCII dwango