ニューラルネットワークでは入力層から出力層の間に複数の中間層を設ける事ができ、各層を入力層から順番に1層目、2層目、、、と数えていきます。各層のノードは次の層のノードにつながっていて、次の層のノードは前の層の全ノードと重みとの内積を取り、それに活性化関数をかけてノードの値を決定していきます(全結合型)。
この内積を取る部分や活性化関数で処理する部分をレイヤと呼びます。
ニューラルネットワークでは重みを更新する必要があり、誤差逆伝播法を用いるため、各レイヤはそれぞれ順方向と逆方向の関数を含みます。
内積を取る部分はAffineレイヤ、活性化関数はReLUやSigmoidなどを使いますので、これらをクラスとして実装していきます。
投稿者: jave
Pythonのファイルをコンパイル
Pythonで作ったプログラムを、そのうちPythonが入っていないPCでも実行したくなるよね、という事で、Exe化するソフトを使ってみました。
Pyinstallerというソフトです。
インストールは下記の通り。
pip install pyinstaller
使い方は下記の通り。
pyinstaller test.py
一つのファイルにまとめるオプションや、コンソールを開かないオプションなどがあるようです。
pyinstaller --onefile --noconsole test.py
一つのファイルにまとめる事が出来るのは便利そうですよね。
で、早速やってみたところ …
OSError: Python library not found: libpython3.6.so.1.0, libpython3.6mu.so.1.0, libpython3.6m.so.1.0
あれ?うまく行ってない。Pythonライブラリの3.6が入っていないようです。
そんなばかな、うちのPCには3.6が入っているはずです。
python -V Python 3.6.5 :: Anaconda, Inc.
ほらね。
しばらく調べたところ、、、
私のPCの/usr/lib64/にはlibpython2.7.soが入っている。
あれ?3.6.5はどこ?
大分調べたところ、anacondaをインストールしたフォルダにあるようで、ここはリンクが貼られていない様子。
私はhomeにanacondaをインストールしたので、下記のところにありましたよ。
/home/user/anaconda3/lib
なるほどーそうかー。
これをLD_LIBRARY_PATHに追加すればよいようです。
.bashrcに下記を書き加えます。書き換えるファイルはOSなどの環境によって違いますね。
export LD_LIBRARY_PATH="/home/user/anaconda3/lib:$LD_LIBRARY_PATH"
ターミナルをいったん閉じてまた開ける。
再度pyinstallerを実行して、無事にexeがdistフォルダの中にできました。結構時間かかりますね。
anacondaをインストールした時に、インストーラが.bachrcを書き換えたのは見ていたのですが、binを追加しただけで、pathは追加されていなかったようです。
出来たファイルを実行してみましょう。
./test
うまく行きました。さほど深くはまらずにできて良かった。
これ、linux上でコンパイルしたんですが、windowsでも動くのかな?と思い、windows10にコピーしてきてやってみましたが、それはダメでした。
そりゃそうか。
試しに他のlinuxにtestをコピーしてみたら、無事動きました。
ところで、コンパイルの方法にはバイトコンパイルというものもあるそうです。
バイトコンパイル
python -m compileall test.py
__pycache__の中に.pycというファイルがあり、これが実行形式なのだそう。
実行環境が改善する事があるそうですが、、、今の私の小さいプログラムだとありがたみが分かりませんね。
Cupyを使ってみる
Pythonでの計算はnumpyを使って行列計算を行うと非常に早く実行できますが、それでも桁が大きくなってくるとそれなりに待たされてしまいます。
GPUを使った行列計算はCPUを使ったものよりも、劇的に早くなる可能性を秘めているとの事ですが、なかなか実装が難しそう。
そんな中、CupyというNumpyと互換性のあるライブラリがChainerの一部として存在するそうです。
とても簡単に実行できるのだそう。やってみようやってみよう。
Cupyのインストールはpipで行えるそう。
pip install cupy-cuda91
特に問題なくインストールも完了。
cuda[xx]の部分はバージョンを入れるようです。
ちなみにcudaのバージョンを調べるのは
nvcc -V
で出来ましたよ。
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2017 NVIDIA Corporation Built on Fri_Nov__3_21:07:56_CDT_2017 Cuda compilation tools, release 9.1, V9.1.85
私の環境では9.1ですね。
それではCupyを使って計算速度を測ってみましょう。
ちなみに私のPCの環境は、
CPU : Intel Core i7 6800K 6コア 12スレッド 3.4GHz
GPU : GeForce GTX 1080Ti 11GB
メモリー : 32GB DDR4-2400
ストレージ : 480GB SSD
OS : CentOS 7.4
となっておりました。いろいろ使えそう。
ちなみにそれぞれのコマンドラインからの調べ方は
CPCの種類の確認 :
cat /proc/cpuinfo
GPUの種類の確認 :
lspci | grep -i VGA
メモリーの確認 :
cat /proc/meminfo
OS :
cat /etc/redhat-release
で調べられます。すぐ忘れるのでメモ必須です。
では早速Cupyを試しましょう。サイトにある例を少しもじります。
10000 x 10000の行列をfloatで作成し、内積を取ります。
timeを使って時間を測り、時間を出力します。
まずはnumpyから。
import numpy as np
import time
N_size = 10000
x = np.random.rand(N_size, N_size).astype('f4')
y = np.random.rand(N_size, N_size).astype('f4')
start = time.time()
np.dot(x, y)
elapsed_time = time.time() - start
print("numpy :{0}".format(elapsed_time))
test.pyと名前つけて保存して実行。
python test.py numpy :4.0388100147247314
10000 x 10000なのでそれなりにかかりますよね。
ではこれをCupyに変えてみます。
import cupy as cp
import time
N_size = 10000
x = cp.random.rand(N_size, N_size).astype('f4')
y = cp.random.rand(N_size, N_size).astype('f4')
start = time.time()
cp.dot(x, y)
elapsed_time = time.time() - start
print("cupy :{0}".format(elapsed_time))
ほんとにそのままですね。これを保存して実行。
python test.py cupy :0.1345818042755127
うん、早くなった。
更に、numpyで用意していた変数をGPUに移すには以下のようにするらしいです。
import numpy as np
import cupy as cp
import time
N_size = 10000
x = np.random.rand(N_size, N_size).astype('f4')
y = np.random.rand(N_size, N_size).astype('f4')
x_cp = cp.asarray(x)
y_cp = cp.asarray(y)
start = time.time()
cp.dot(x_cp, y_cp)
elapsed_time = time.time() - start
print("cupy :{0}".format(elapsed_time))
python test.py cupy :0.17929410934448242
あれ?さっきより遅くなった。そういう、、、ものなのかな?
numpyを使ってみる
numpyをインポートします。
行列計算を行っていくにはnumpyが基本になります。
numpyで変数を定義し、デフォルトで配列を使っていくイメージです。
配列の演算を行うとき、Cではforを使って一つずつ回していたものをなるべくnumpyの関数を用いて実装する事で、処理が高速になります。
例えばベクトルの内積はこちら。Notebookに下記のように打ち込んで、Runを押すと結果が見れます。
import numpy as np x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) z = np.dot(x, y) print(z) >> 32
内積なので、1×4 + 2×5 + 3×6 = 4 + 10 + 18 = 32 ですね。うん合ってる。
ベクトルの内積だけでなく、行列の内積も同じです。
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array([[7, 8, 9], [10, 11, 12]])
z = np.dot(x, y)
print(z)
>> [ [ 27 30 33]
[ 61 68 75]
[ 95 106 117] ]
行列計算になると一気に数字が増えますね。
この例ですと、xは3×2行列、yは2×3行列となり、zは3×3行列となります。
行の数と列の数を明示的に示す場合に、
x = np.array([ [1, 2],
[3, 4],
[5, 6] ])
とあらわす場合もあるようです。
行 : 横長1セットが3つ、
列 : 縦長1セットが2つ、
ですので、3×2行列です。
数学での行列計算と同じく、xの列の数とyの行の数が一致しないと計算できないので注意してください。
場合によっては転置が必要な場合もあります。
Pythonでの転置行列は.Tです。
print(x.T)
>> [ [1 3 5]
[2 4 6] ]
この辺りをうまく使って、for文をなるべく回避するのが、Pythonプログラムの基本のようです。
ライブラリをインクルード
Pythonではimportというそうです。輸入。
まずはnumpyをインクルードしてみます。
numpyは行列計算を実行する時に使うライブラリです。
ノートブックを開き、下記のように打ち込んで、Runをクリック。
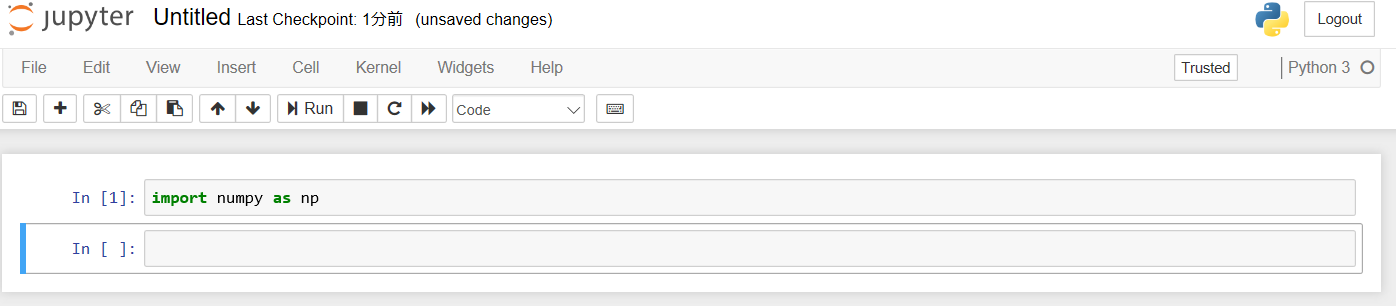
特にエラーがでなければimport成功です。
もしエラーがでるようであればnumpyがPCにインストールされていないようです。
その場合はプロンプトを開き、下記のコマンドでインストールできます。
pip install numpy
同じ感じでグラフを扱うときはMatplotlib、データ解析の時はPandasなどをimportしていきます。
また自分で作ったクラスも同じ感じでimportして使います。
from common.mycode import mydefinedclass
commonフォルダにある、mycode.pyファイルの中で定義されているmydefinedclassをimportするよ、という意味になります。
自分でclassを実装して行って、実行ファイルではそれを読み込んで実施する、といった流れになります。
なぜPythonなのか
なぜPythonなのでしょうか?(2回言っちゃった。)
私が学生の時は、まずはFortrun, 実質C++, 少しトレンディな人はJavaでした。
今でも正式な商用プログラムの多くはC++で書かれているようですし、企業が求める人材としてもCはトップです。
なぜDeep LearningではPythonなのか?(3回目になっちゃった。)
2018年度の人気プログラミング言語を徹底比較! (TECH ACADEMYさんのページです)
やはり人気のようです。
「でもPythonってインタプリタじゃん。実行遅いじゃん。」
Deep Learningのような計算負荷が高いものを実装するのに、何故にわざわざ遅いプログラミング言語を選ぶのか。
行列計算をうまい事使えば、Pythonでも早い実装は出来ますよ、といった記述はよく見かけます。
しかしそのためにはPythonの特徴を理解した上で、上手な実装が必要になるわけで、そうしたらPythonの利点の一つである、シンプルで習得しやすいという特徴が無くなりませんかね…?
この辺りがひっかかって、Pythonにはしばらく手を出していませんでした。
今回の事がきっかけで使い続けていくうち、自分でもすっきりした答えが見つかるといいなーと思いつつ、あまり深く考えないようにしようと思います。
今日は単なる雑談でしたね。
AIとはなにか?
AI (Artificial Intelligence) とはなにか
教科書によると、
「定型的な労働を自動化し、
言葉や画像を理解し、
基礎科学研究を支援する知的なソフトウェア」
とあります。
人工知能研究の初期の段階では、
「人間にとっては難解だが、コンピュータにとっては容易な課題を解決する目的」
で研究が進んでいきました。
人間がやると大変な作業を定型化し、コンピュータに任せる事で世の中の作業性は格段に改善しました。
これは現在のパソコンの普及を見れば、大いに理解できます。しかしながら、今ではこれはあまり人工知能とは呼ばないようです。
人工知能研究における研究のチャレンジ(難解な課題)は、むしろ
「人間にとって実行するのは簡単だが、形式的に記述するのが難しいタスクを解決する事」
の方でした。
画像認識や音声認識などは人間が行うのは容易だけれでも、コンピュータにおいてはアナログな情報の解析や、それをもとにした判断は大変困難で、これまでの手法では実現不可能であったわけです。
近年の人工知能業界の大きな盛り上がりは、これら画像認識や音声認識において、大きなブレイクスルーがあったためと思われます。
AIの研究はずっと昔から行われていて、現在に至るまでいくつかのブームも経験しています。
どこからを人工”知能”と呼ぶかは難しいところですが、初期の頃の人工知能は論理的なルール作成は全て人の手で構築されていました。

推論モデルを構築し、新しい結果を予測するために、過去のデータを用いていた事から、Knowledge Baseアプローチと呼ばれています。ここでは大量のデータの中からどの部分に着目するのか、そのデータをどのように扱ってモデル化するのか、など、全て人の手で行われます。従って比較的単純な課題であれば機能するものの、少し複雑なタスクになればその普遍的なルール作りが人の手に負えなくなり、期待した成果が挙げられませんでした。
そこでデータにおける普遍的なルールを自ら構築するシステムが考えられました。入力データに対して機械がルールの修正を自動で行う事で、徐々に正しい答えを導けるようになるプロセスが人間の学習と似ていた事から、これを機械学習(Machine Learning)と呼んでいます。
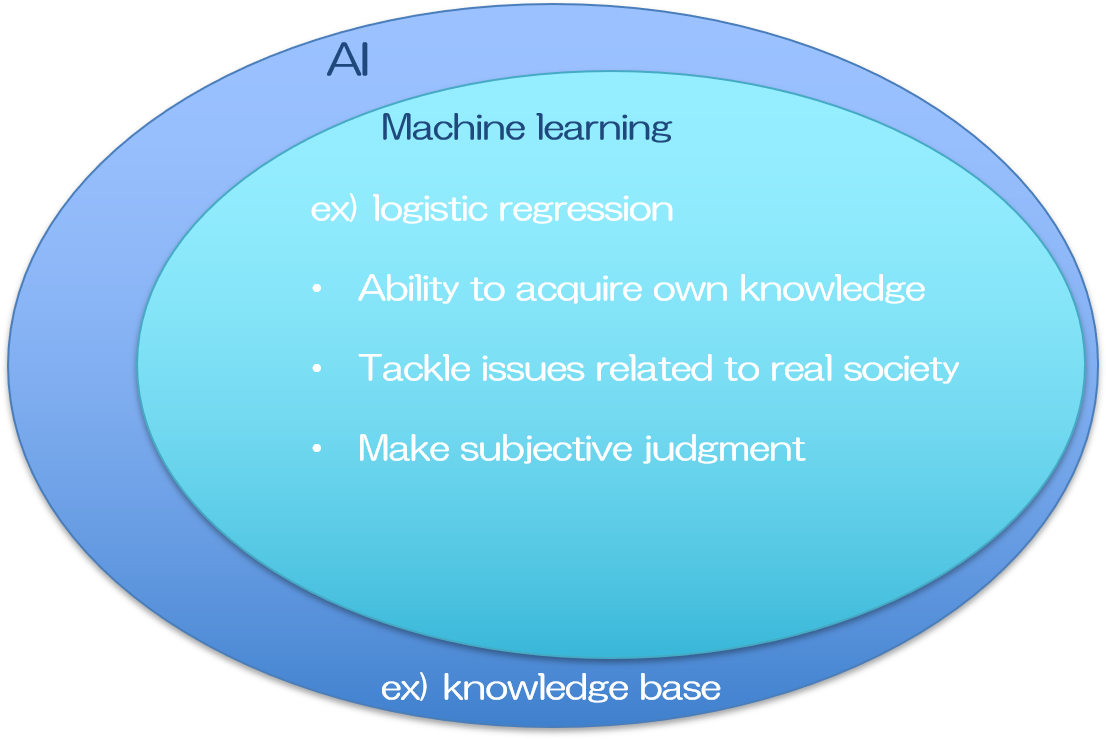
過去のデータを用いるので、結局はKnowledge Baseですが、複雑なルールで成り立つ課題であっても、大量のデータさえあれば何かしらの論理モデルを構築する事ができ、現実社会における問題を解決し得る答えを提供できる可能性があるため、大変な進歩を遂げたと言えます。
一方で、大量のデータの中からどの情報(特徴量)に着目するかは、依然人の手で指定する必要がありました。写真に写っているのが男性か女性かを識別するモデルであれば、男性の特徴は○○で○○である、女性の特徴は××で××である、など。
注目すべき特徴が明らかである場合は大変有効なモデルが構築できます。また注目すべき特徴をとにかくたくさん認識させておいて、どの特徴量が結果ともっとも強い相関があるかを調べる方法もあります。
しかしながら特徴量がそもそも曖昧なケースには適応できませんし、求めたい課題一つ一つに、有効な特徴量を検討する必要が生じ、わざわざ時間をかけてモデルを構築する用途は限られていました。
そこで注目すべき特徴量そのものも、入力データから自動で抽出できるシステムが考えられました。代表的なものに、ニューラルネットワークという機械学習の一分野を応用した、自己符号化器(オートエンコーダ, autoencoder)が挙げられます。
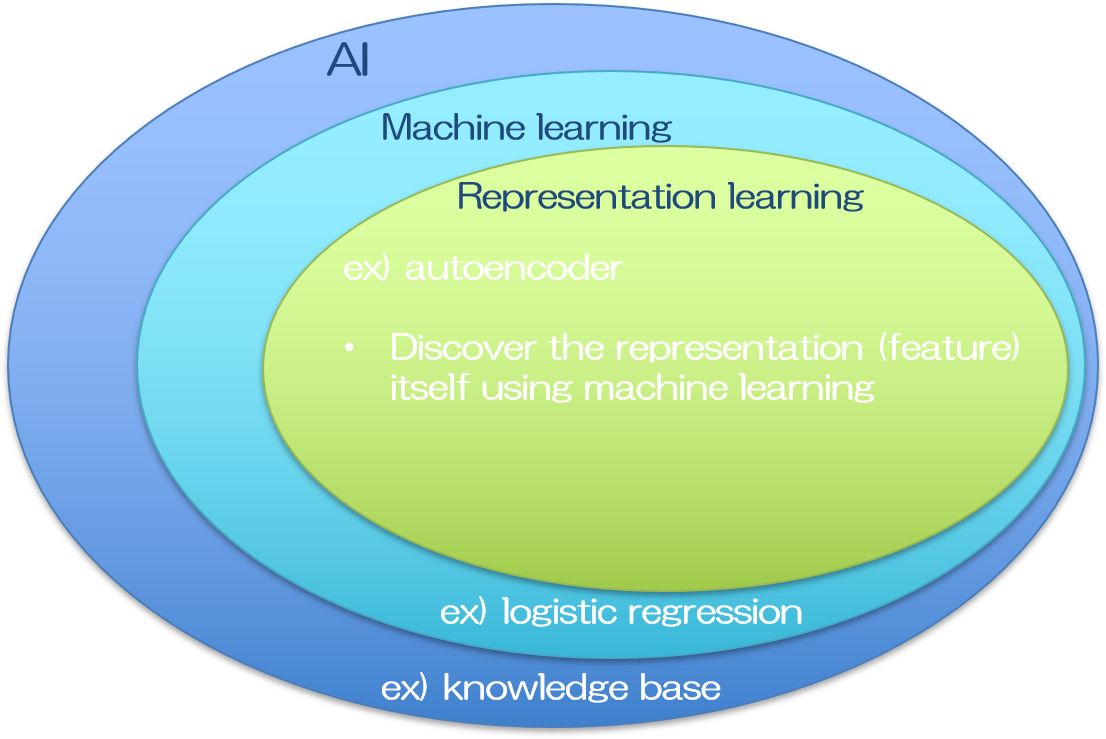
オートエンコーダは入力と出力に同じデータを入れて学習を行います。入力データはエンコーダで変換され、その変換されたデータはデコーダによって復元されます。デコーダからの出力は入力データと等価でなくてはならないので、デコーダの入力である、エンコーダで変換されたデータは、入力の中でも特に重要な特徴量を含むことになります。
このように特徴量まで自動抽出してくれるシステムを得た事により、人工知能は飛躍的に使い勝手が良くなりました。人間は入力データさえ持っていれば、あとは機械が全てやってくれます(理想的には。実際にはそうは行きませんが)。
ちなみに機械学習と一口に言っても、その手法は多岐に渡ります。どの手法が究極的な人工知能を構築するのに適しているのか。長い間たくさんの研究が行われました。ニューラルネットワークはそのうちの一手法であって、ディープラーニングも昔からその構想は提案されてきた、概念自体は歴史の長い手法になります。精度の高いディープラーニングの登場によって人工知能の可能性は脚光を浴びる事になりましたが、将来的に究極の人工知能がどの手法を用いて実現されるかは、まだ分かりません。近年のブームをけん引するディープラーニングが注目されたのは、AlexNetの登場によるものと思われます。
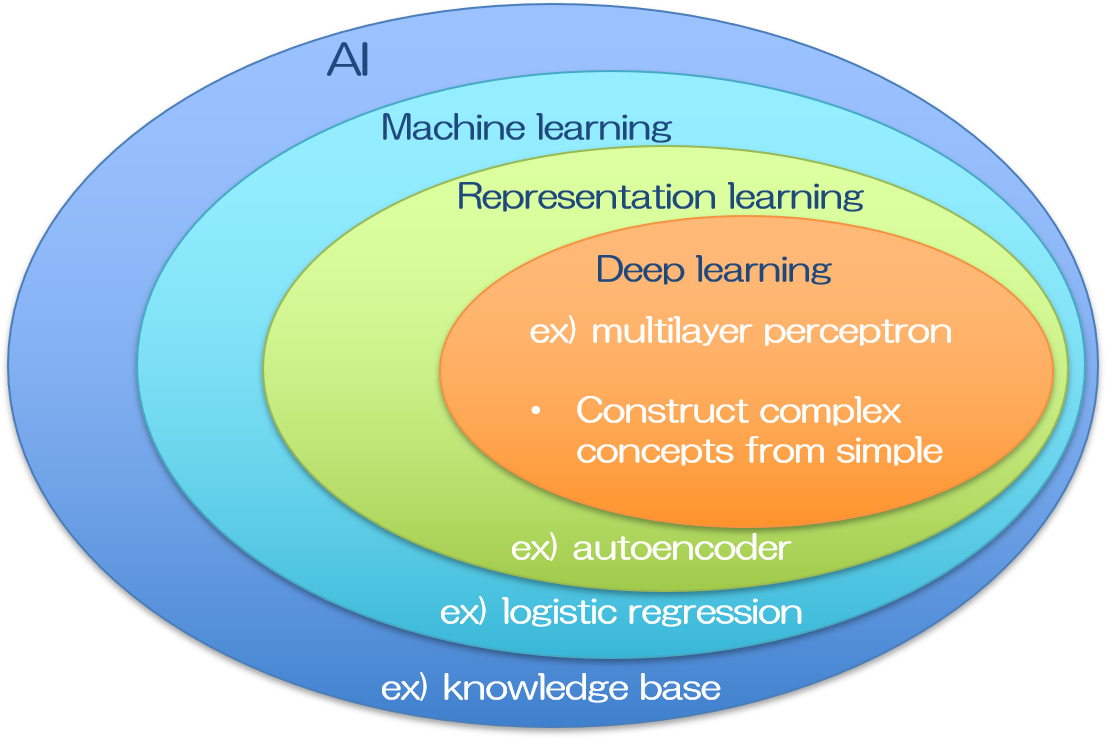
人間の脳のニューロンを模したと言われるニューラルネットワークは、パーセプトロンの繋がりで表現される比較的シンプルな形をしており、層構造になっています。層を深くすればするほど複雑なネットワークとなり、同時に複雑な事象を表現できると思われますが、実際には層を深くするほど伝達される情報が少なくなる問題がありました。これは勾配損失と呼ばれています。上記のAlexNetはこの問題をReLU関数を活性化関数に用いる事で解決しました(と私は習いましたが、AlexNetの凄さはそれだけではないかもしれません)。
AlexNetの登場を皮切りに、勾配損失の問題をうまく工夫して回避する事で、ディープラーニングの層構造を深くすることができ、その結果として従来よりもネットワークの精度を飛躍的に向上させる事に成功しました。今では入力画像として猫の画像を大量に用意するだけで、写真に写っている動物が猫なのか犬なのか狸なのかを識別してくれるモデルが、誰にでも作ることができます。
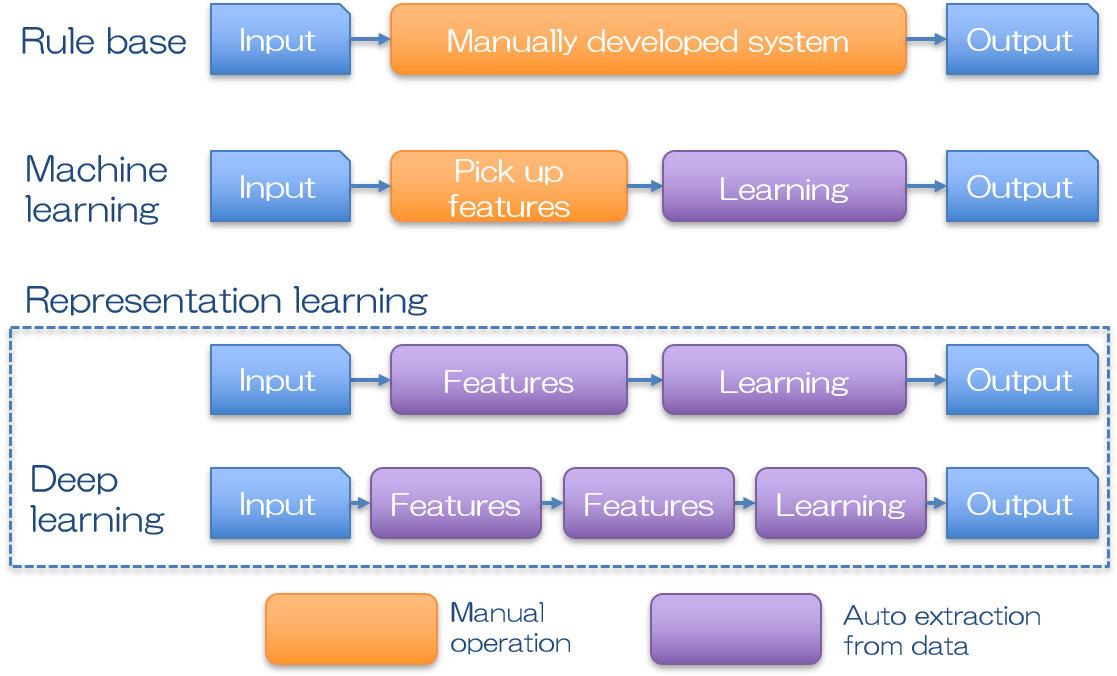
人工知能の手法の分類には色々と異論があるところもあります。そもそも、それぞれの境は少々あいまいで、どこからの多層パーセプトロンがニューラルネットワークなのか、何層からのニューラルネットワークがディープラーニングなのかは、明確な定義はないそうです。またニューラルネットワークは機械学習の一分野なので、上記のベン図のように書いてしまうと、機械学習の最先端はディープラーニングしか無いように見えてしまいますが、他の手法も研究されています。
今後AI研究がどのような方向に進むのかは分かりませんが、現在は最先端のツールが安価で使えるすごい時代でありますので、その時代の恩恵に預り、ありがたく使わせていただこうと思う次第です。
[参考]
Ian Goodfellow著
深層学習 (Deep learning)
ASCII dwango

Webサイトの開設
Webサイトによる情報の発信は大変大切です!
… と私の先生はおっしゃっていました …
Deep Learningとは関係ないですが、Webサイトの開設も同時に行ったので記録しておきます。とは言え、今更Webサイトの作り方なんて、情報があふれていますので、ここではごく簡単に記載します。あまり余計な事を読まずに、とにかく始めたいだけの方にはむしろこちらの方が良いかも。
Webサイトを開設するには下記の3点が必要になります。
1. サーバーの取得、登録
2. ドメインの取得、登録
3. WordPressのインストール
サーバーとドメインはイマイチ違いが分かりづらいですが、
サーバーはモノを置いておく倉庫のようなもの。
ドメインはサーバーを置いてある住所のようなもの。
といったイメージでしょうか。
サーバーにHPに必要なパーツを組み立てて置いておいて、ユーザーはドメインを頼りに、そのパーツにアクセスしにくる感じです。
3のWordPressは別に使わなくてもいいですが、大変簡単にWebサイトが作れますので、多くの人が使っています。以前はHTMLを直接書いてHPを作っていた時代もありましたが、それではなかなかキレイなページは作れないんですよね。センスがないと。
WordPressの利用は初めは斜め上から見ていて躊躇していましたが、今ではスッカリWordPress色に染まっています。
それでは順番に行きましょう。
まずはサーバーを取得しに行きます。
1. サーバーの取得、登録
色々ありますが、私はXserverを使っています。
定番のWebサーバーとの事です。
以前は無料のXdomainを使っていましたが、お引越ししました。
理由は以前の私のHPがどうもモッサリしていたからです。
それがXdomainのせいかは分かりませんが、Xserverに変えてからは劇的に快適になりました。
Xserverへの登録はこちらからできます。
![]()
X10プランで、1年間契約だと毎月1,000円かかります。
始めはこれがネックでXdomainの無料サーバーを使っていました。
Web作成初心者はXdomainの無料サーバーでよろしいかと思います。
少し試してみて、続けられそうであれば、より快適なXserverにお引越ししましょう。
他にはLoliPopというサーバーも大変人気です。
LoliPopを使われる方はこちらから。
![]()
2. ドメインの取得、登録
倉庫が借りれましたら、次は住所の申請に行きます。 Xserverを登録した時点で、〇〇.xsrv.jpというドメインが無料でいただけます。 HPを作るだけならこれだけで良いです。作成したページに問題なくアクセスできます。
一方で商用ページを作るとか、アクセスしやすいようにHPの名前を反映した名前を付けたいとか、カワイイ名前が付けたいとか、その他もろもろの理由により名前を変更したい場合は、ドメインの方も取得する必要があります。 ドメインの取得において、もっとも有名なのがお名前ドットコムです。
住所の取得にはお金がかかります。以前のXdomain![]() を使っていた時は私もこちらにお世話になっていたのですが、Xserverに移行した時にキャンペーンでドメインが一つもらえたので、必要なくなってしまいました。
を使っていた時は私もこちらにお世話になっていたのですが、Xserverに移行した時にキャンペーンでドメインが一つもらえたので、必要なくなってしまいました。
3. WordPressのインストール
ここまできたらあともう少し。次はWordPressをインストールします。
Xserverのサーバーパネルにログインすると、WordPress簡単インストールというボタンがあるので、それをクリックし、後は指示通り進めていくだけです。全て完了すると、WordPressのログインページにブラウザから入れるようになり、HPの実際の構築が始まります。
実際の登録の仕方などは全て省いて紹介しましたが、ここでは流れを紹介しました。具体的な方法はたくさん情報がありますので、そちらで調べてみてください。
MeCabのインストール
MeCabをインストールします。
以前はソースコードからコンパイルする必要があったそうですが、いまはapt-getでお手軽簡単とのことです。
MeCabをapt-getでインストールしてから、Python3で使うためにmecab-python3なるものもインストールしています。
sudo apt-get install mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8 pip install mecab-python3
このmecab-python3を入れるときに、swigが入っていないと失敗する事があります。
error: command 'swig' failed with exit status 1 ---------------------------------------- Failed building wheel for mecab-python3 Running setup.py clean for mecab-python3 Failed to build mecab-python3 Installing collected packages: mecab-python3 Running setup.py install for mecab-python3 ... error
swigを入れるとうまく行きます。
sudo apt-get -q -y install swig pip install mecab-python3
MeCabのバージョンは
mecab -v
で調べられます。私のは、、、version 0.996ですね。
ImportError: No module named ‘_bz2’
Pythonでbz2をインポートして使おうとしたところ、
ImportError: No module named '_bz2'
と言うエラーが出た。bz2は圧縮されたファイルであるという意味の拡張子との事。
Ubuntuでpyenvを用いているの場合は、下記のようにすればよいそうです。
sudo apt-get install libbz2-dev pyenv install --force 3.6.0
3.6.0の部分は使用しているPythonのバージョンです。
libbz2-devを再インストールすると、Pythonの再インストールも必要なのだとか。